-
Windows 시스템 로캘, Unicode와 UTF-8 (feat. MySQL)CS 2024. 1. 6. 04:19
~ 프롤로그 ~
MySQL 쓰려는데 이런 문제가 발생했다.

아래 글을 참고하여 해결하였고, 결과적으로는
"MySQL 8.0에서 유니코드 인코딩 된 것을 Windows11환경에서 CP949로 읽으려고하니 문제가 발생한 건가보다."
라고 생각하고있다.
My sql workbench error 에러 해결 : could not acquire management access for administration - QUANT PRO
1. 윈도우 언어 설정 접속2. 시스템 로캘변경 클릭 -> 아래 체크박스 클릭 🥕 위의 방법대로 시행한 후 재부팅을 하면 에러가 없어진다!! 환경변수 path 추가 : C:WindowsSystem32
quantpro.co.kr
이 문제에 대해서 고민하다가
시스템 로캘, Unicode, UTF-8에 대해 다시 좀 공부해보면서
위와 같은 결론을 내렸기 때문에
그 내용과 과정을 좀 정리 해보려고 한다.
~ System Locale 시스템 로캘 ~
각 국가별로 언어, 시간, 통화 등 정보는 다르다.
이러한 정보를 묶어서 표시할 수 있는 개념이 Locale이다.
위의 사진처럼 현재 시스템 로캘을 '한국어(대한민국)'으로 설정하면
내 인터페이스는 한국어, 한국 시간 등으로 세팅되는 것이다.위 방법은 OS에서 설정된 것으로, 일괄적으로 Locale을 변경한 것이지만
Locale Categories라고 해서, 자신의 입맛에 맞게 세부적인 지정도 가능하다고 한다.
(특정 작업을 할 때에만 언어를 영어로 설정하는 등)
~ Unicode, UTF-8 ~
1. Unicode
컴퓨터는 숫자로 구성되는데, 문자를 컴퓨터에서 표현하려면 어떻게 해야할까?
숫자와 문자로 매핑시켜서 표시해두고 사용할 수 있을 것이다. 바로 코드표다!
대표적으로 ASCII가 있다. (예) 10진수 65 -> 'A' )
초창기에는 ASCII 위주로 표현을 했다(1byte로도 충분히 표현 가능)
그러나 전 세계의 다양한 문자를 쓰는 이들도 컴퓨터를 사용해야하지 않겠는가!!
그래서 그들도 1byte의 남는 공간에 어찌저찌 자기네들의 문자를 매핑해서 쓰긴 했으나,
이메일이나 웹페이지 등에서 글자가 다 깨져버렸다ㅜ.
그래서 글자당 4byte라는 넉넉한 공간을 할당하면서,
전세계 문자들을 매핑하는 표준 코드표를 정했다.
바로 Unicode다!
2. UTF-8
ASCII가 1byte라고 언급했듯이, 알파벳은 1byte로도 다 표현된다.
(1byte = 8bit, 2^8 = 256인데 알파벳 대소문자 52자+숫자 10자+기호들 다 합쳐도 256이 안 넘으니까요)
한편, 한글은 글자수가 넘 많아서 1byte에 다 안 들어간다.
이렇게 각 나라의 문자들은 저마다 표현되는 크기가 다르다. (가변적으로 표현된다.)
컴퓨터: 그럼 나 1byte로 해, 2byte로 해?? 3byte인가??? 헷갈려!!
그래서 몇 byte로 저장할지 같이 표시를 하게되었다.
바로 인코딩이다!
유니코드 문자 인코딩 표준은 UTF-16, UTF-8, USC-2 등 다양하다.
그 중에서도 UTF-8은 가장 많이 사용되는 가변 길이 인코딩 방식이다. (+ Go Lang 만든 사람이 만들었대서 신기하다)
ASCII와의 호환성 + 여러 장점... 등 때문이라고.
~ MySQL 에러를 돌아보자 ~
저는 OS로 Windows11을 사용하고 있어요.
Linux나 Mac에서는 UTF-8이 기본이지만,
Windows11은 UTF-8(Unicode형 표현 방법)이 아니라
CP949(확장 완성형 표현 방법)으로 한글을 지원한다고 한다.
즉, MySQL 인코딩이 Unicode라면 CP949과 호환이 안 되므로 제대로 읽지 못할 것이다
MySQL 8.0을 쓰고있는데, 현재 인코딩을 확인하기 위해서 CLI를 열었다.
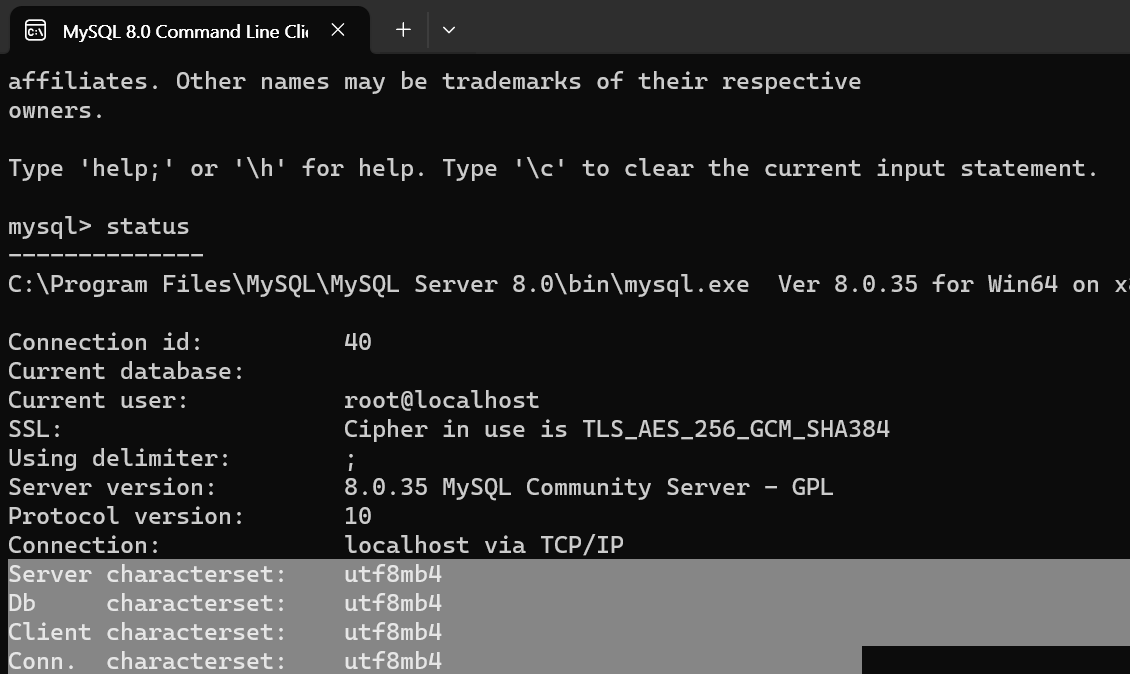
status를 입력해서 위와 같은 정보를 확인했다.
characterset이 utf8mb4다!!
UTF-8은 4byte를 사용한다( + 6byte까지 가능하지만 다른 인코딩 호환을 위해 4byte 사용한다고.)
한편, MySQL이나 MariaDB에서는 성능상 문제로 UTF-8이 3byte로 구현 되는 uft8인코딩 이라고 한다.
즉, UFT-8과 uft8은 다른 것이다.
그러나 최근에는 Emoji와 같은 4byte문자열도 표현해야해서
MySQL은 utf8mb4를 도입했다고 한다.
아무튼 Unicode호환을 위해
'세계 언어지원을 위해 Unicode UTF-8을 사용'을 표시했다.
이후에는 MySQL에서 처음과 같은 에러가 사라졌다.
개발 하다가 인코딩에 대한 지식이 없어 골치가 아픈 경우도 종종 있다고 한다
앞으로도 틈틈히 공부를 해두면 좋을 것 같다!
'CS' 카테고리의 다른 글
Code - 문자를 컴퓨터에 저장하는 방식 (0) 2023.03.09